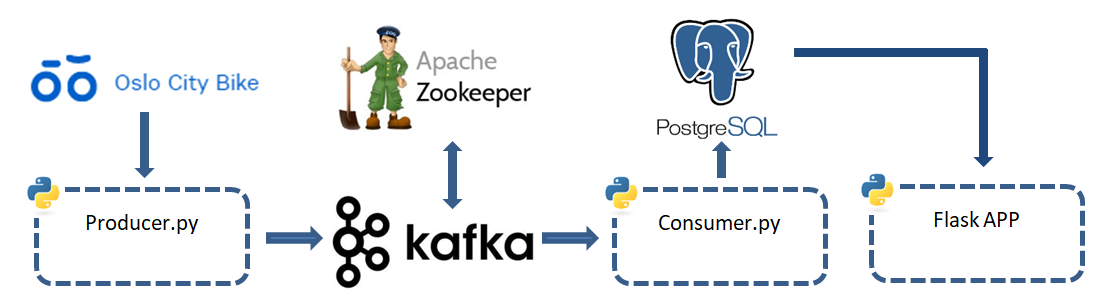
End to End Distributed Queue with Kafka, PostgreSQL and Python
This article purpose is to introduce essential Kafka concept, through an example of data pipeline.
We will build an end to end data pipeline that will allow us to monitor live data about the Oslo City Bike.
The goal is to see available docks & bikes in real time, change in status and represent them in map.


Contents
- Running Zookeeper
- Running Kafka
- Creating a Topic
- Creating a Producer with python
- Creating a PostgreSQL Database with python and psycopg2
- Creating a Consumer with python
- Rendering Data with python Flask using efficient and advanced SQL techniques
Running Zookeeper
Zookeeper acts as a centralized service that will store metadata for the broker and provide flexible synchronization with Kafka cluster nodes, topics and partitions
You can follow this detailed tutorial to install Zookeeper by Shahrukh Aslam
Open comand prompt and type zkserver to start our Zookeeper server
zkserverRunning Kafka
Apache Kafka is a community distributed event streaming platform capable of handling events at large scale. Kafka is based on an abstraction of a distributed commit log. Kafka became along the year the top event streaming platform.
You can follow this excellent tutorial to install Kafka written by Shahrukh Aslam
open new command prompt and go to your kafka folder
cd C:\Tools\kafka_2.13-2.7.0.\bin\windows\kafka-server-start.bat .\config\server.properties
Topic Creation
Kafka records are stored and published in a Topic.
Producers send data to the Topic while consumers get data from it.
Open new command prompt and go to the window folder of your kafka folder
Create a new topic “test” with the below command line
cd C:\Tools\kafka_2.13-2.7.0\bin\windowskafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Producer
In this section we will create a producer in python that sends message to our kafka broker. This message will later be consumed by the consumer and stored into our postgresql DataWarehouse
We will create a python script called producer.py
First we import the library that will be used in our small script :
from time import sleep
from json import dumps
from kafka import KafkaProducer #via pip install Kafka-Python
import requestsNext we will intialize the kakfa producer
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:
dumps(x).encode('utf-8'))Now we want to get the real time data from the Oslo City Bike API
We will send the data to the Kafka Brokere each 30 seconds
for i in range(120): #60 Minutes
headers = {
'Client-Identifier': 'dan-citymonitor',
}
response = requests.get('https://gbfs.urbansharing.com/oslobysykkel.no/station_status.json', headers=headers)
r = response.json()
producer.send('test', value=r)
sleep(30)PostgreSQL
PostgreSQL is an OLTP Database. OLTP Stands for Online Transaction Processing. OLTP Database are known to be fast on CRUD operation for small numbers of rows. They are not to be confused with OLAP Database ( Online Analytical Processing ) that are more designed toward analytic purposes on large dataset ( HIVE/BIGQUERY/SNOWFLAKES…).
Before creating our consumer that will load the data into our database we will build our dataset and table.
For that we will use the most popular module psycopg2 to connect to postgresql via Python
pip install psycopg2we now create our table Station_Status in our database Oslo_City_Bike
import psycopg2
conn = psycopg2.connect(
database="oslo_city_bike", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
cursor = conn.cursor()#Creating Database Oslo_city_bikesql = '''CREATE database OSLO_City_Bike''';
cursor.execute(sql)
conn.commit()#Creating Table Station_Statuscursor.execute("DROP TABLE IF EXISTS Station_Status")
sql ='''CREATE TABLE Station_Status(
Station_id CHAR(20) NOT NULL,
is_installed INT,
is_renting INT,
is_returning INT,
last_reported INT,
num_bikes_available INT,
num_docks_available INT
)'''
cursor.execute(sql)
conn.commit()
conn.close()
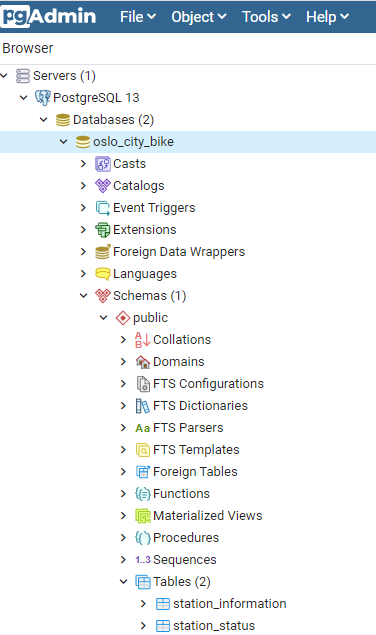
We can now check if the table is available in PGadmin
Consumer
Now that the producer is created and is sending the data to our Kafka Broker, and that we have our SQL Database ready, we will create a consumer script named consumer.py that will retrieve the data from Kafka and store it into PostgreSQL.
First we import the library that will be used in our small script :
from kafka import KafkaConsumer
from json import loads
from datetime import datetime
import psycopg2We initialize the consumer :
consumer = KafkaConsumer(
'test',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group',
value_deserializer=lambda x: loads(x.decode('utf-8')))We connect to our Postgresql database using psycopg2 library
conn = psycopg2.connect( database="oslo_city_bike", user='postgres', password='password', host='127.0.0.1', port= '5432')
cursor = conn.cursor()We load into our database the data requested by the producer on the Oslo City Bike API
for message in consumer:
message = message.value
timestamp = message['last_updated']
dt_object = datetime.fromtimestamp(timestamp)
message['Date'] = dt_object.strftime("%b %d %Y %H:%M:%S")
datehrs = dt_object.strftime("%b %d %Y %H:%M:%S")
for station in message['data']['stations']:
cursor.execute("INSERT INTO Station_Status (Station_id, is_installed, is_renting, is_returning,last_reported,num_bikes_available,num_docks_available,date) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)", (station['station_id'],station['is_installed'],station['is_renting'],station['is_returning'],station['last_reported'],station['num_bikes_available'],station['num_docks_available'],dt_object))
conn.commit()
print('Data at {} added to POSTGRESQL'.format(dt_object, collection))
conn.close()Results
Our Data Pipeline is finished, we can now work on rendering the data for user information.
Every 30 seconds our producer is sending to Kafka the full information regarding the bikes and docks availability, then our consumer retrieve it and load the data into our Oslo_City_Bike database, under the table Station_Status.
To flag change and create our interactive map we will need to check for changes in availability on each timestamps.
One way to get a log of all our movement accross all stations is to create an SQL query that will rank the data by timestamps and station and then compare the availability of the row versus the previous timestamps.
To do that we will use several SQL Technique such as CTEs, Subquery or derived table
Let’s use CTE to create a derived table, using window function LAG
WITH
T1 as
(select
station_id,
num_bikes_available,
num_docks_available,
date,
last_reported,
LAG(last_reported,1) over (partition by station_id order by last_reported) as prevtime,
LAG(date,1) over (partition by station_id order by last_reported) as prevdate
from
station_status)
The above derived table T1 allow us to map the previous timestamps to the current row. In the above print we can see that row 1, the previous timestamps of 18h45h47 is 18:45:25.
We can now use subquery to test if the number of bikes or docks changed vs the previous data :
select
station_information.name,
t1.station_id,
right(t1.date,9) as date,
t1.num_bikes_available,
t1.num_docks_available,
t1.prevdate,
T2.num_bikes_available,
t1.num_bikes_available-T2.num_bikes_available as Change,
concat(station_information.lat,',',station_information.lon) as Coordinate
from
t1
inner join
(select * from station_status) as T2
ON
T1.station_id = T2.station_id
AND
T1.prevtime = T2.last_reported
inner join
station_information
ON
T1.station_id = station_information.station_id
where (t1.num_bikes_available-T2.num_bikes_available) <>0
order by
t1.date desc
We can now render all this information to be more user friendly using Python-Flask (not detailed here as it’s not the topic of the article)
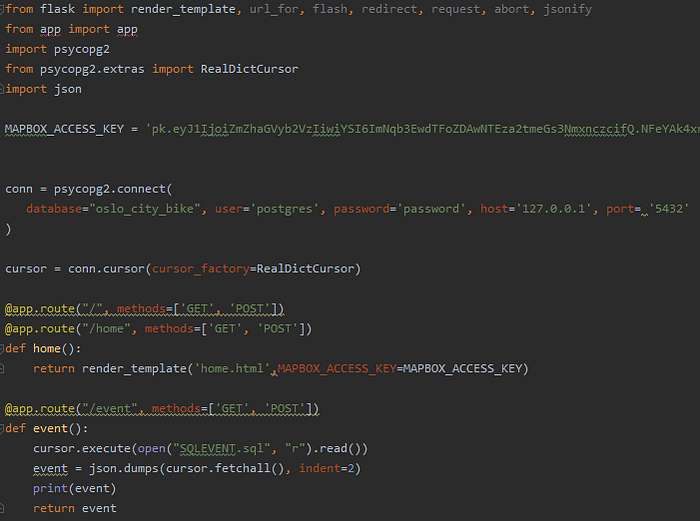
Thats it ! we created an entire Data Pipeline with real time data using Python , Kafka/Zookeeper and PostgreSQL!
Please feel free to highlight any mistakes to me in the comments section or by dropping a private message !
